Системные вызовы. Man syscalls (2): системные вызовы Linux Линукс описание системных вызовов ядра
Системные вызовы
Пока что все программы, которые мы сделали должны были использовать хорошо определенные механизмы ядра, чтобы регистрировать /proc файлы и драйверы устройства. Это прекрасно, если Вы хотите делать что-то уже предусмотренное программистами ядра, например писать драйвер устройства. Но что, если Вы хотите сделать что-то необычное, изменить поведение системы некоторым способом?
Это как раз то место, где программирование ядра становится опасным. При написании примера ниже, я уничтожил системный вызов open . Это подразумевало, что я не могу открывать любые файлы, я не могу выполнять любые программы, и я не могу закрыть систему командой shutdown . Я должен выключить питание, чтобы ее остановить. К счастью, никакие файлы не были уничтожены. Чтобы гарантировать, что Вы также не будете терять файлы, пожалуйста выполните sync прежде чем Вы отдадите команды insmod и rmmod .
Забудьте про /proc файлы и файлы устройств. Они только малые
детали. Реальный процесс связи с ядром, используемый всеми процессами,
это системные вызовы. Когда процесс запрашивает обслуживание из ядра (типа
открытия файла, запуска нового процесса или запроса большего количества
памяти), используется этот механизм. Если Вы хотите изменить поведение ядра
интересными способами, это как раз подходящее место. Между прочим, если Вы
хотите видеть какие системные вызовы использованы программой, выполните:
strace
Вообще, процесс не способен обратиться к ядру. Он не может обращаться к памяти ядра и не может вызывать функции ядра. Аппаратные средства CPU предписывают такое положение дел (недаром это называется `protected mode" (защищенный режим)). Системные вызовы исключение из этого общего правила. Процесс заполняет регистры соответствующими значениями и затем вызывает специальную команду, которая переходит к предварительно определенному месту в ядре (конечно, оно читается процессами пользователя, но не перезаписывается ими). Под Intel CPUs, это выполнено посредством прерывания 0x80. Аппаратные средства знают, что, как только Вы переходите к этому месту, Вы больше не работаете в ограниченном режиме пользователя. Вместо этого Вы работаете как ядро операционной системы, и следовательно вам позволено делать все, что Вы хотите сделать.
Место в ядре, к которому процесс может переходить, названо system_call . Процедура, которая там находится, проверяет номер системного вызова, который сообщает ядру чего именно хочет процесс. Затем, она просматривает таблицу системных вызовов (sys_call_table), чтобы найти адрес функции ядра, которую надо вызвать. Затем вызывается нужная функция, и после того, как она возвращает значение, делается несколько проверок системы. Затем результат возвращается обратно процессу (или другому процессу, если процесс завершился). Если Вы хотите посмотреть код, который все это делает, он находится в исходном файле arch/ < architecture > /kernel/entry.S , после строки ENTRY(system_call) .
Так, если мы хотим изменить работу некоторого системного вызова, то первое, что мы должны сделать, это написать нашу собственную функцию, чтобы она выполняла соответствующие действия (обычно, добавляя немного нашего собственного кода, и затем вызывая первоначальную функцию), затем изменить указатель в sys_call_table , чтобы указать на нашу функцию. Поскольку мы можем быть удалены позже и не хотим оставлять систему в непостоянном состоянии, это важно для cleanup_module , чтобы восстановить таблицу в ее первоначальном состоянии.
Исходный текст, приводимый здесь, является примером такого модуля. Мы хотим "шпионить" за некоторым пользователем, и посылать через printk сообщение всякий раз, когда данный пользователь открывает файл. Мы заменяем системный вызов, открытия файла нашей собственной функцией, названной our_sys_open . Эта функция проверяет uid (user id) текущего процесса, и если он равен uid, за которым мы шпионим, вызывает printk , чтобы отобразить имя файла, который будет открыт. Затем вызывает оригинал функции open с теми же самыми параметрами, фактически открывает файл.
Функция init_module меняет соответствующее место в sys_call_table и сохраняет первоначальный указатель в переменной. Функция cleanup_module использует эту переменную, чтобы восстановить все назад к норме. Этот подход опасен, из-за возможности существования двух модулей, меняющих один и тот же системный вызов. Вообразите, что мы имеем два модуля, А и B. Системный вызов open модуля А назовем A_open и такой же вызов модуля B назовем B_open. Теперь, когда вставленный в ядро системный вызов заменен на A_open, который вызовет оригинал sys_open, когда сделает все, что ему нужно. Затем, B будет вставлен в ядро, и заменит системный вызов на B_open, который вызовет то, что как он думает, является первоначальным системным вызовом, а на самом деле является A_open.
Теперь, если B удален первым, все будет хорошо: это просто восстановит системный вызов на A_open, который вызывает оригинал. Однако, если удален А, и затем удален B, система разрушится. Удаление А восстановит системный вызов к оригиналу, sys_open, вырезая B из цикла. Затем, когда B удален, он восстановит системный вызов к тому, что он считает оригиналом, На самом деле вызов будет направлен на A_open, который больше не в памяти. На первый взгляд кажется, что мы могли бы решать эту специфическую проблему, проверяя, если системный вызов равен нашей функции open и если так, не менять значение этого вызова (так, чтобы B не изменил системный вызов, когда удаляется), но это вызовет еще худшую проблему. Когда А удаляется, он видит, что системный вызов был изменен на B_open так, чтобы он больше не указывал на A_open, так что он не будет восстанавливать указатель на sys_open прежде, чем будет удалено из памяти. К сожалению, B_open будет все еще пробовать вызывать A_open, который больше не в памяти, так что даже без удаления B система все равно рухнет.
Я вижу два способа предотвратить эту проблему. Первое: восстановить обращение к первоначальному значению sys_open. К сожалению, sys_open не является частью таблицы ядра системы в /proc/ksyms , так что мы не можем обращаться к нему. Другое решение состоит в том, чтобы использовать счетчик ссылки, чтобы предотвратить выгрузку модуля. Это хорошо для обычных модулей, но плохо для "образовательных" модулей.
/* syscall.c
*
* System call "stealing" sample
*/
/* Copyright (C) 1998-99 by Ori Pomerantz */
/* The necessary header files */
/* Standard in kernel modules */
#include
Данный материал является модификацией одноименной статьи Владимира Мешкова, опубликованной в журнале "Системный администратор"
Данный матрериал являеться копиями статей Владимира Мешкова с журанала "Системный администратор". Данные статьи могут быть найдены по приведенным ниже ссылкам. Так же были изменены некоторые примеры исходных текстов программ - улучшены, доработаны. (Сильно изменен пример 4.2, так как пришлось перехватывать немного другой системный вызов) URLs: http://www.samag.ru/img/uploaded/p.pdf http://www.samag.ru/img/uploaded/a3.pdf
Есть вопросы? Тогда вам сюда: [email protected]
- 2. Загружаемый модуль ядра
- 4. Примеры перехвата системных вызовов на основе LKM
- 4.1 Запрет создания каталогов
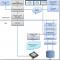
1. Общий взгяд на архитектуру Linux
Самый общий взгяд позволяет увидеть двухуровневую модель системы. kernel <=> progs В центре (слева) находиться ядро системы. Ядро непосредственно взаимодействует, с аппаратной частью компьютера, изолируя прикладные программы от особенностей архитектуры. Ядро имеет набор услуг предоставляемых прикладным программам. К услугам ядра относятся операции ввода/вывода (открытия, чтения, записи и управление файлами), создание и управление процессами, их синхронизации и межпроцессного взаимодействия. Все приложения запрашивают услуги ядра посредством системных вызовов.Второй уровень составляют приложения или задачи, как системные, определяющие функциональность системы, так и прикладные, обеспечивающие пользовательский интерфейс Linux. Однако не смотря на внешнюю разнородность приложений, схемы взаимодействия с ядром одинаковы.
Взаимодействие с ядром происходит посредством стандартного интерфейса системных вызовов. Интерфейс системных вызовов представляет собой набор услуг ядра и определяет формат запросов на услуги. Процесс запрашивает услугу посредством системного вызова определенной процедуры ядра, внешне похожего на обычный вызов библиотечной функции. Ядро от имени процесса выполняет запрос и возвращает процессу необходимые данные.
В приведенном примере программа открывает файл, считывает из него данные и закрывает этот файл. При этом операция открытия (open), чтения (read) и закрытия (close) файла выполняются ядром по запросу задачи, а функция open(2), read(2) и close(2) являются системными вызовами.
/* Source 1.0 */
#include
- в регистр EAX - номер системного вызова. Так, для нашего случая номер системного вызова равен 5 (см. __NR_open).
- в регистр EBX - первый параметр функции (для open() - это указатель на строку, содержащую имя открываемого файла.
- в регистр ECX - второй параметр (права доступа к файлу)
Чтобы убедиться, что мы на правильном пути, рассмотрим код функции open() в системной библиотеке libc:
# gdb -q /lib/libc.so.6
(gdb) disas open
Dump of assembler code for function open:
0x000c8080
А теперь давайте вернемся к рассмотрению механизма системных вызовов. Итак, ядро вызывает обработчик прерывания 0x80 - функцию system_call. System_call помещает копии регистров, содержащих параметры вызова в стэк, при помощи макроса SAVE_ALL и командой call вызывает нужную системную функцию. Таблица указателей на функции ядра, которые реализуют системные вызовы, расположена в массиве sys_call_table (см. файл arch/i386/kernel/entry.S). Номер системного вызова, который находиться в регистре EAX, является индексом в этом массиве. Таким образом, если в EAX находиться значение 5, будет вызвана функция ядра sys_open(). Зачем нужен макрос SAVE_ALL? Объяснение тут очень простое. Так как практически все системные функции ядра написаны на C, то свои параметры они ищут в стеке. А параметры помещаются в стек при помощи SAVE_ALL! Возвращаемое системным вызовом значение сохраняется в регистр EAX.
Теперь давайте выясним, как перехватить системный вызов. Поможет нам в этом механизм загружаемых модулей ядра.
2. Загружаемый модуль ядра
Загружаемый модуль ядра (общепринятое сокращение LKM - Loadable Kernel Module) - программный код, выполняемый в пространстве ядра. Главной особенностью LKM является возможность динамической загрузки и выгрузки без необходимости перезагрузки всей системы или перекомпиляции ядра.Каждый LKM состоит из двух основных функций (минимум):
- функция инициализации модуля. Вызывается при загрузке LKM в память: int init_module(void) { ... }
- функция выгрузки модуля: void cleanup_module(void) { ... }
3. Алгоритм перехвата системного вызова на основе LKM
Для реализации модуля, перехватывающего системный вызов, необходимо определить алгоритм перехвата. Алгоритм следующий:- сохранить указатель на оригинальный (исходный) вызов для возможности его восстановления
- создать функцию, реализующую новый системный вызов
- в таблице системных вызовов sys_call_table произвести замену вызовов, т.е настроить соответствующий указатель на новый системный вызов
- по окончании работы (при выгрузке модуля) восстановить оригинальный системный вызов, используя ранее сохраненный указатель
4. Примеры перехвата системных вызовов на основе LKM
4.1 Запрет создания каталогов
При создании каталога вызвывается функция ядра sys_mkdir. В качестве параметра задаеться строка, которой содержится имя создаваемого каталога. Рассмотрим код, осуществляющий перехват соответствующего системного вызова. /* Source 4.1 */ #include4.2 Сокрытие записи о файле в каталоге
Определим, какой системный вызов отвечает за чтение содержимого каталога. Для этого напишем еще один тестовый фрагмент, который занимается чтение текущей директории: /* Source 4.2.1 */ #include- d_reclen - размер записи
- d_name - имя файла
5. Метод прямого доступа к адресному пространству ядра /dev/kmem
Рассмотрим сначала теоретически, как осуществляется перехват методом прямого доступа к адресному пространству ядра, а затем приступим к практической реализации.Прямой доступ к адресному пространству ядра обеспечивает файл устройства /dev/kmem. В этом файле отображено все доступное виртуальное адресное пространство, включая раздел подкачки (swap-область). Для работы с файлом kmem используются стандартные системные функции - open(), read(), write(). Открыв стандартным способом /dev/kmem, мы можем обратиться к любому адресу в системе, задав его как смещение в этом файле. Данный метод был разработан Silvio Cesare.
Обращение к системным функциям осуществляется посредством загрузки параметров функции в регистры процессора и последующим вызовом программного прерывания 0x80. Обработчик этого прерывания, функция system_call, помещает параметры вызова в стэк, извлекает из таблицы sys_call_table адрес вызываемой системной функции и передает управление по этому адресу.
Имея полный доступ к адресному пространству ядра, мы можем получить все содержимое таблицы системных вызовов, т.е. адреса всех системных функций. Изменив адрес любого системного вызова, мы, тем самым, осуществим его перехват. Но для этого необходимо знать адрес таблицы, или, другими словами, смещение в файле /dev/kmem, по которому эта таблица расположена.
Чтобы определить адрес таблицы sys_call_table, предварительно необходимо вычислить адрес функции system_call. Поскольку данная функция является обработчиком прерывания, давайте рассмотрим, как обрабатываются прерывания в защищенном режиме.
В реальном режиме процессор при регистрации прерывания обращается таблице векторов прерываний, находящейся всегда в самом начале памяти и содержащей двусловные адреса программ обработки прерываний. В защищенном режиме аналогом таблице векторов прерываний является таблица дескрипторов прерываний (IDT, Interrupt Descriptor Table), располагающаяся в операционной системе защищенного режима. Для того, чтобы процессор мог обратиться к этой таблице, ее адрес следует загрузить в регистр IDTR (Interrupt Descriptor Table Register, регистр таблицы дескрипторов прерываний). Таблица IDT содержит дескрипторы обработчиков прерываний, в которые, в частности, входят их адреса. Эти дескрипторы называются шлюзами (вентилями). Процессор, зарегистрировав прерывание, по его номеру извлекает из IDT шлюз, определяет адрес обработчика и передает ему управление.
Для вычисления адреса функции system_call из таблицы IDT необходимо извлечь шлюз прерывания int $0x80, а из него - адрес соответствующего обработчика, т.е. адрес функции system_call. В функции system_call обращение к таблице system_call_table выполняется командой call <адрес_таблицы>(,%eax,4). Найдя опкод (сигнатуру) этой команды в файле /dev/kmem, мы найдем и адрес таблицы системных вызовов.
Для определения опкода воспользуемся отладчиком и дизассемблируем функцию system_call:
# gdb -q /usr/src/linux/vmlinux
(gdb) disas system_call
Dump of assembler code for function system_call:
0xc0194cbc
Рассмотрим псевдокод, выполняющий операцию перехвата:
Readaddr (old_syscall, scr + SYS_CALL*4, 4); writeaddr (new_syscall, scr + SYS_CALL*4, 4); Функция readaddr считывает адрес системного вызова из таблицы системных вызовов и сохраняет его в переменной old_syscall. Каждая запись в таблице sys_call_table занимает 4 байта. Искомый адрес расположен по смещению sct + SYS_CALL*4 в вайле /dev/kmem (здесь sct - адрес таблицы sys_call_table, SYS_CALL - порядковый номер системного вызова). Функция writeaddr перезаписывает адрес системного вызова SYS_CALL адресом функции new_syscall, и все обращения к системного вызову SYS_CALL будут обслуживаться этой функцией.
Кажеться, все просто и цель достигнута. Однако давайте вспомним, что мы работает в адресном пространстве пользователя. Если разместить новую системную функцию в этом адресном пространстве, то при вызове этой функции мы получим красивое сообщение об ошибке. Отсюда вывод - новый системный вызов необходимо разместить в адресном пространстве ядра. Для этого необходимо: получить блок памяти в пространстве ядра, разместить в этом блоке новый системный вызов.
Выделить память в пространстве ядра можно при помощи функции kmalloc. Но вызвать напрямую функцию ядра из адресного пространства пользователя нельзя, поэтому воспользуемся следующим алгоритмом:
- зная адрес таблицы sys_call_table, получаем адрес некоторого системного вызова (например, sys_mkdir)
- определяем функцию, выполняющую обращение к функции kmalloc. Эта функция возвращает указатель на блок памяти в адресном пространстве ядра. Назовем эту функцию get_kmalloc
- сохраняем первые N байт системного вызова sys_mkdir, где N - размер функции get_kmalloc
- перезаписываем первые N байт вызова sys_mkdir функцией get_kmalloc
- выполняем обращение к системному вызову sys_mkdir, тем самым запустив на выполнение функцию get_kmalloc
- восстанавливаем первые N байт системного вызова sys_mkdir
Но для реализации данного алгоритма нам необходим адрес функции kmalloc. Найти его можно несколькими способами. Самый простой - это считать этот адрес из файла System.map или определить с помошью отладчика gdb (print &kmalloc). Если в ядре включена поддержка модулей, адрес kmalloc можно определить при помощи функции get_kernel_syms(). Этот вариант будет рассмотрен далее. Если же поддержка модулей ядра отсутствует, то адрес функции kmalloc придеться искать по опкоду команды вызова kmalloc - аналогично тому, как было сделано для таблицы sys_call_table.
Функция kmalloc принимает два параметра: размер запрашиваемой памяти и спецификатор GFP. Для поиска опкода воспользуемся отладчиком и дизассемблируем любую функцию ядра, в которой есть вызов функции kmalloc.
# gdb -q /usr/src/linux/vmlinux
(gdb) disas inter_module_register
Dump of assembler code for function inter_module_register:
0xc01a57b4
На этом завершим теоретические выкладки и, используя вышеприведенную методику, осуществим перехват системного вызова sys_mkdir.
6. Пример перехвата средствами /dev/kmem
/* source 6.0 */ #includeEnd Of Paper/EOP
Работоспособность кода из всех разделов была проверена на ядре 2.4.22. При подготовки доклада были использованы материалы сайтаЧаще всего, код системного вызова с номером __NR_xxx, определённого в /usr/include/asm/unistd.h , можно найти в исходном коде ядра Linux в функции sys_xxx (). (Таблицу вызовов для i386 можно найти в /usr/src/linux/arch/i386/kernel/entry.S .) Есть много исключений из этого правила, в основном из-за того, что большинство старых системных вызовов заменена на новые, при чём без всякой системы. На платформах с эмуляцией собственнических ОС, таких как parisc, sparc, sparc64 и alpha, существует много дополнительных системных вызовов; для mips64 также есть полный набор 32-битных системных вызовов.
С течением времени при необходимости происходили изменения в интерфейсе некоторых системных вызовов. Одной из причин таких изменений была необходимость увеличения размера структур или скалярных значений передаваемых системному вызову. Из-за этих изменений на некоторых архитектурах (а именно на старых 32-битных i386) появились различные группы похожих системных вызовов (например, truncate (2) и truncate64 (2)), которые выполняют одинаковые задачи, но отличаются размером своих аргументов. (Как уже отмечалось, на приложения это не влияет: обёрточные функции glibc выполняют некоторые действия по запуску правильного системного вызова, и это обеспечивает совместимость по ABI для старых двоичных файлов.) Примеры системных вызовов, у которых есть несколько версий:
* В настоящее время есть три различные версии stat (2): sys_stat () (место __NR_oldstat ), sys_newstat () (место __NR_stat ) и sys_stat64 () (место __NR_stat64 ), последняя используется в в данный момент. Похожая ситуация с lstat (2) и fstat (2). * Похожим образом определены __NR_oldolduname , __NR_olduname и__NR_uname для вызовов sys_olduname (), sys_uname () и sys_newuname (). * В Linux 2.0 появилась новая версия vm86 (2), новая и старая версии ядерных процедур называются sys_vm86old () и sys_vm86 (). * В Linux 2.4 появилась новая версия getrlimit (2) новая и старая версии ядерных процедур называются sys_old_getrlimit () (место __NR_getrlimit ) и sys_getrlimit () (место __NR_ugetrlimit ). * В Linux 2.4 увеличено размер поля ID пользователей и групп с 16 до 32 бит. Для поддержки этого изменения добавлено несколько системных вызовов (например, chown32 (2), getuid32 (2), getgroups32 (2), setresuid32 (2)), упраздняющих ранние вызовы с теми же именами, но без суффикса "32". * В Linux 2.4 добавлена поддержка доступа к большим файлам (у которых размеры и смещения не умещаются в 32 бита) в приложениях на 32-битных архитектурах. Для этого потребовалось внести изменения в системные вызовы, работающие с размерами и смещениями по файлам. Были добавлены следующие системные вызовы: fcntl64 (2), getdents64 (2), stat64 (2), statfs64 (2), truncate64 (2) и их аналоги, которые обрабатывают файловые дескрипторы или символьные ссылки. Эти системные вызовы упраздняют старые системные вызовы, которые, за исключением вызовов «stat», называются также, но не имеют суффикса «64».
На новых платформах, имеющих только 64-битный доступ к файлам и 32-битные UID/GID (например, alpha, ia64, s390x, x86-64), есть только одна версия системных вызовов для UID/GID и файлового доступа. На платформах (обычно это 32-битные платформы) где имеются *64 и *32 вызовы, другие версии устарели.
* Вызовы rt_sig* добавлены в ядро 2.2 для поддержки дополнительных сигналов реального времени (см. signal (7)). Эти системные вызовы упраздняют старые системные вызовы с теми же именами, но без префикса "rt_". * В системных вызовах select (2) и mmap (2) используется пять или более аргументов, что вызывало проблемы определения способа передачи аргументов на i386. В следствии этого, тогда как на других архитектурах вызовы sys_select () и sys_mmap () соответствуют __NR_select и __NR_mmap , на i386 они соответствуют old_select () и old_mmap () (процедуры, использующие указатель на блок аргументов). В настоящее время больше нет проблемы с передачей более пяти аргументов и есть __NR__newselect , который соответствует именно sys_select (), и такая же ситуация с __NR_mmap2 .
ВЛАДИМИР МЕШКОВ
Перехват системных вызовов в ОС Linux
За последние годы операционная система Linux прочно заняла лидирующее положение в качестве серверной платформы, опережая многие коммерческие разработки. Тем не менее вопросы защиты информационных систем, построенных на базе этой ОС, не перестают быть актуальными. Существует большое количество технических средств, как программных, так и аппаратных, которые позволяют обеспечить безопасность системы. Это средства шифрования данных и сетевого трафика, разграничения прав доступа к информационным ресурсам, защиты электронной почты, веб-серверов, антивирусной защиты, и т. д. Список, как вы понимаете, достаточно длинный. В данной статье предлагаем вам рассмотреть механизм защиты, основанный на перехвате системных вызовов операционной системы Linux. Данный механизм позволяет взять под контроль работу любого приложения и тем самым предотвратить возможные деструктивные действия, которые оно может выполнить.
Системные вызовы
Начнем с определения. Системные вызовы – это набор функций, реализованных в ядре ОС. Любой запрос приложения пользователя в конечном итоге трансформируется в системный вызов, который выполняет запрашиваемое действие. Полный перечень системных вызовов ОС Linux находится в файле /usr/include/asm/unistd.h. Давайте рассмотрим общий механизм выполнения системных вызовов на примере. Пусть в исходном тексте приложения вызывается функция creat() для создания нового файла. Компилятор, встретив вызов данной функции, преобразует его в ассемблерный код, обеспечивая загрузку номера системного вызова, соответствующего данной функции, и ее параметров в регистры процессора и последующий вызов прерывания 0x80. В регистры процессора загружаются следующие значения:
- в регистр EAX – номер системного вызова. Так, для нашего случая номер системного вызова будет равен 8 (см. __NR_creat);
- в регистр EBX – первый параметр функции (для creat это указатель на строку, содержащую имя создаваемого файла);
- в регистр ECX – второй параметр (права доступа к файлу).
В регистр EDX загружается третий параметр, в данном случае он у нас отсутствует. Для выполнения системного вызова в ОС Linux используется функция system_call, которая определена в файле /usr/src/liux/arch/i386/kernel/entry.S. Эта функция – точка входа для всех системных вызовов. Ядро реагирует на прерывание 0x80 обращением к функции system_call, которая, по сути, представляет собой обработчик прерывания 0x80.
Чтобы убедиться, что мы на правильном пути, напишем небольшой тестовый фрагмент на ассемблере. В нем увидим, во что превращается функция creat() после компиляции. Файл назовем test.S. Вот его содержание:
Globl _start
Text
Start:
В регистр EAX загружаем номер системного вызова:
movl $8, %eax
В регистр EBX – первый параметр, указатель на строку с именем файла:
movl $filename, %ebx
В регистр ECX – второй параметр, права доступа:
movl $0, %ecx
Вызываем прерывание:
int $0x80
Выходим из программы. Для этого вызовем функцию exit(0):
movl $1, %eax movl $0, %ebx int $0x80
В сегменте данных укажем имя создаваемого файла:
Data
filename: .string "file.txt"
Компилируем:
gcc -с test.S
ld -s -o test test.o
В текущем каталоге появится исполняемый файл test. Запустив его, мы создадим новый файл с именем file.txt.
А теперь давайте вернемся к рассмотрению механизма системных вызовов. Итак, ядро вызывает обработчик прерывания 0x80 – функцию system_call. System_call помещает копии регистров, содержащих параметры вызова, в стек при помощи макроса SAVE_ALL и командой call вызывает нужную системную функцию. Таблица указателей на функции ядра, которые реализуют системные вызовы, расположена в массиве sys_call_table (см. файл arch/i386/kernel/entry.S). Номер системного вызова, который находится в регистре EAX, является индексом в этом массиве. Таким образом, если в EAX находится значение 8, будет вызвана функция ядра sys_creat(). Зачем нужен макрос SAVE_ALL? Объяснение тут очень простое. Так как практически все системные функции ядра написаны на С, то свои параметры они ищут в стеке. А параметры помещаются в стек при помощи макроса SAVE_ALL! Возвращаемое системным вызовом значение сохраняется в регистр EAX.
Теперь давайте выясним, как перехватить системный вызов. Поможет нам в этом механизм загружаемых модулей ядра. Хотя ранее мы уже рассматривали вопросы разработки и применения модулей ядра, в интересах последовательности изложения материала рассмотрим кратко, что такое модуль ядра, из чего он состоит и как взаимодействует с системой.
Загружаемый модуль ядра
Загружаемый модуль ядра (обозначим его LKM – Loadable Kernel Module) – это программный код, выполняемый в пространстве ядра. Главной особенностью LKM является возможность динамической загрузки и выгрузки без необходимости перезагрузки всей системы или перекомпиляции ядра.
Каждый LKM состоит из двух основных функций (минимум):
- функция инициализации модуля. Вызывается при загрузке LKM в память:
int init_module(void) { ... }
- функция выгрузки модуля:
void cleanup_module(void) { ... }
Приведем пример простейшего модуля:
#define MODULE
#include
int init_module(void)
printk("Hello World ");
return 0;
void cleanup_module(void)
printk("Bye ");
Компилируем и загружаем модуль. Загрузку модуля в память осуществляет команда insmod:
gcc -c -O3 helloworld.c
insmod helloworld.o
Информация обо всех загруженных в данный момент в систему модулях находится в файле /proc/modules. Чтобы убедиться, что модуль загружен, введите команду cat /proc/modules либо lsmod. Выгружает модуль команда rmmod:
rmmod helloworld
Алгоритм перехвата системного вызова
Для реализации модуля, перехватывающего системный вызов, необходимо определить алгоритм перехвата. Алгоритм следующий:
- сохранить указатель на оригинальный (исходный) вызов для возможности его восстановления;
- создать функцию, реализующую новый системный вызов;
- в таблице системных вызовов sys_call_table произвести замену вызовов, т.е. настроить соответствующий указатель на новый системный вызов;
- по окончании работы (при выгрузке модуля) восстановить оригинальный системный вызов, используя ранее сохраненный указатель.
Выяснить, какие системные вызовы задействуются при работе приложения пользователя, позволяет трассировка. Осуществив трассировку, можно определить, какой именно системный вызов следует перехватить, чтобы взять под контроль работу приложения. Пример использования программы трассировки будет рассмотрен ниже.
Теперь у нас достаточно информации, чтобы приступить к изучению примеров реализации модулей, осуществляющих перехват системных вызовов.
Примеры перехвата системных вызовов
Запрет создания каталогов
При создании каталога вызывается функция ядра sys_mkdir. В качестве параметра задается строка, в которой содержится имя создаваемого каталога. Рассмотрим код, осуществляющий перехват соответствующего системного вызова.
#include
#include
#include
Экспортируем таблицу системных вызовов:
extern void *sys_call_table;
Определим указатель для сохранения оригинального системного вызова:
int (*orig_mkdir)(const char *path);
Создадим собственный системный вызов. Наш вызов ничего не делает, просто возвращает нулевое значение:
int own_mkdir(const char *path)
return 0;
Во время инициализации модуля сохраняем указатель на оригинальный вызов и производим замену системного вызова:
int init_module()
orig_mkdir=sys_call_table;
sys_call_table=own_mkdir; return 0;
При выгрузке восстанавливаем оригинальный вызов:
void cleanup_module()
Sys_call_table=orig_mkdir;
Код сохраним в файле sys_mkdir_call.c. Для получения объектного модуля создадим Makefile следующего содержания:
CC = gcc
CFLAGS = -O3 -Wall -fomit-frame-pointer
sys_mkdir_call.o: sys_mkdir_call.c
$(CC) -c $(CFLAGS) $(MODFLAGS) sys_mkdir_call.c
Командой make создадим модуль ядра. Загрузив его, попытаемся создать каталог командой mkdir. Как вы можете убедиться, ничего при этом не происходит. Команда не работает. Для восстановления ее работоспособности достаточно выгрузить модуль.
Запрет чтения файла
Для того чтобы прочитать файл, его необходимо вначале открыть при помощи функции open. Легко догадаться, что этой функции соответствует системный вызов sys_open. Перехватив его, мы можем защитить файл от прочтения. Рассмотрим реализацию модуля-перехватчика.
#include
#include
#include
#include
#include
#include
#include
extern void *sys_call_table;
Указатель для сохранения оригинального системного вызова:
int (*orig_open)(const char *pathname, int flag, int mode);
Первым параметром функции open является имя открываемого файла. Новый системный вызов должен сравнить этот параметр с именем файла, который мы хотим защитить. Если имена совпадут, будет сымитирована ошибка открытия файла. Наш новый системный вызов имеет вид:
int own_open(const char *pathname, int flag, int mode)
Сюда поместим имя открываемого файла:
char *kernel_path;
Имя файла, который мы хотим защитить:
char hide="test.txt"
Выделим память и скопируем туда имя открываемого файла:
kernel_path=(char *)kmalloc(255,GFP_KERNEL);
copy_from_user(kernel_path, pathname, 255);
Сравниваем:
if(strstr(kernel_path,(char *)&hide) != NULL) {
Освобождаем память и возвращаем код ошибки при совпадении имен:
kfree(kernel_path);
return -ENOENT;
else {
Если имена не совпали, вызываем оригинальный системный вызов для выполнения стандартной процедуры открытия файла:
kfree(kernel_path);
return orig_open(pathname, flag, mode);
int init_module()
orig_open=sys_call_table;
sys_call_table=own_open;
return 0;
void cleanup_module()
sys_call_table=orig_open;
Сохраним код в файле sys_open_call.c и создадим Makefile для получения объектного модуля:
CC = gcc
CFLAGS = -O2 -Wall -fomit-frame-pointer
MODFLAGS = -D__KERNEL__ -DMODULE -I/usr/src/linux/include
sys_open_call.o: sys_open_call.c
$(CC) -c $(CFLAGS) $(MODFLAGS) sys_open_call.c
В текущем каталоге создадим файл с именем test.txt, загрузим модуль и введем команду cat test.txt. Система сообщит об отсутствии файла с таким именем.
Честно говоря, такую защиту легко обойти. Достаточно командой mv переименовать файл, а затем прочесть его содержимое.
Сокрытие записи о файле в каталоге
Определим, какой системный вызов отвечает за чтение содержимого каталога. Для этого напишем еще один тестовый фрагмент, который занимается чтением текущей директории:
/* Файл dir.c*/
#include
#include
int main ()
DIR *d;
struct dirent *dp;
d = opendir(«.»);
dp = readdir(d);
Return 0;
Получим исполняемый модуль:
gcc -o dir dir.c
и выполним его трассировку:
strace ./dir
Обратим внимание на предпоследнюю строку:
getdents (6, /* 4 entries*/, 3933) = 72;
Содержимое каталога считывает функция getdents. Результат сохраняется в виде списка структур типа struct dirent. Второй параметр этой функции является указателем на этот список. Функция возвращает длину всех записей в каталоге. В нашем примере функция getdents определила наличие в текущем каталоге четырех записей – «.», «..» и два наших файла, исполняемый модуль и исходный текст. Длина всех записей в каталоге составляет 72 байта. Информация о каждой записи сохраняется, как мы уже сказали, в структуре struct dirent. Для нас интерес представляют два поля данной структуры:
- d_reclen – размер записи;
- d_name – имя файла.
Для того чтобы спрятать запись о файле (другими словами, сделать его невидимым), необходимо перехватить системный вызов sys_getdents, найти в списке полученных структур соответствующую запись и удалить ее. Рассмотрим код, выполняющий эту операцию (автор оригинального кода – Michal Zalewski):
extern void *sys_call_table;
int (*orig_getdents)(u_int, struct dirent *, u_int);
Определим свой системный вызов.
int own_getdents(u_int fd, struct dirent *dirp, u_int count)
unsigned int tmp, n;
int t;
Назначение переменных будет показано ниже. Дополнительно нам понадобятся структуры:
struct dirent *dirp2, *dirp3;
Имя файла, который мы хотим спрятать:
char hide=»our.file»;
Определим длину записей в каталоге:
tmp=(*orig_getdents)(fd,dirp,count);
if(tmp>0){
Выделим память для структуры в пространстве ядра и скопируем в нее содержимое каталога:
dirp2=(struct dirent *)kmalloc(tmp,GFP_KERNEL);
сopy_from_user(dirp2,dirp,tmp);
Задействуем вторую структуру и сохраним значение длины записей в каталоге:
dirp3=dirp2;
t=tmp;
Начнем искать наш файл:
while(t>0) {
Считываем длину первой записи и определяем оставшуюся длину записей в каталоге:
n=dirp3->d_reclen;
t-=n;
Проверяем, не совпало ли имя файла из текущей записи с искомым:
if(strstr((char *)&(dirp3->d_name),(char *)&hide) != NULL) {
Если это так, затираем запись и вычисляем новое значение длины записей в каталоге:
memcpy(dirp3,(char *)dirp3+dirp3->d_reclen,t);
tmp-=n;
Позиционируем указатель на следующую запись и продолжаем поиск:
dirp3=(struct dirent *)((char *)dirp3+dirp3->d_reclen);
Возвращаем результат и освобождаем память:
copy_to_user(dirp,dirp2,tmp);
kfree(dirp2);
Возвращаем значение длины записей в каталоге:
return tmp;
Функции инициализации и выгрузки модуля имеют стандартный вид:
int init_module(void)
orig_getdents=sys_call_table;
sys_call_table=own_getdents;
return 0;
void cleanup_module()
sys_call_table=orig_getdents;
Сохраним исходный текст в файле sys_call_getd.c и создадим Makefile следующего содержания:
CC = gcc
module = sys_call_getd.o
CFLAGS = -O3 -Wall
LINUX = /usr/src/linux
MODFLAGS = -D__KERNEL__ -DMODULE -I$(LINUX)/include
sys_call_getd.o: sys_call_getd.c $(CC) -c
$(CFLAGS) $(MODFLAGS) sys_call_getd.c
В текущем каталоге создадим файл our.file и загрузим модуль. Файл исчезает, что и требовалось доказать.
Как вы понимаете, рассмотреть в рамках одной статьи пример перехвата каждого системного вызова не представляется возможным. Поэтому тем, кто заинтересовался данным вопросом, рекомендую посетить сайты:
Там вы сможете найти более сложные и интересные примеры перехвата системных вызовов. Обо всех замечаниях и предложениях пишите на форум журнала.
При подготовке статьи были использованы материалы сайта